
In this fast-paced digital era, speech recognition technology has evolved as an extremely powerful tool, transforming the way we interact with computers, smartphones, and other devices. In the past, speech technology was based on limited statistics and probability through machine learning. Today, speech technology has evolved radically with the use of deep learning and neural networks which mimic the workings and modelling of the human brain and how we interpret sounds.
Powered by deep learning and neural networks, speech recognition technology has made remarkable advancements in highly accurately transcribing human speech into written reports and documentation. In this blog, we will explore exactly what deep learning and neural networks are and why we use this technology in our speech recognition SDK.
What are neural networks?
Neural networks are simulated by the most complex and sophisticated object, the human brain. According to a 2009 study, the human brain is made up of roughly 86 billion neurons (geeksforgeeks, 2023). A neuron is the simplest unit of any neural network. This is where information processing takes place.
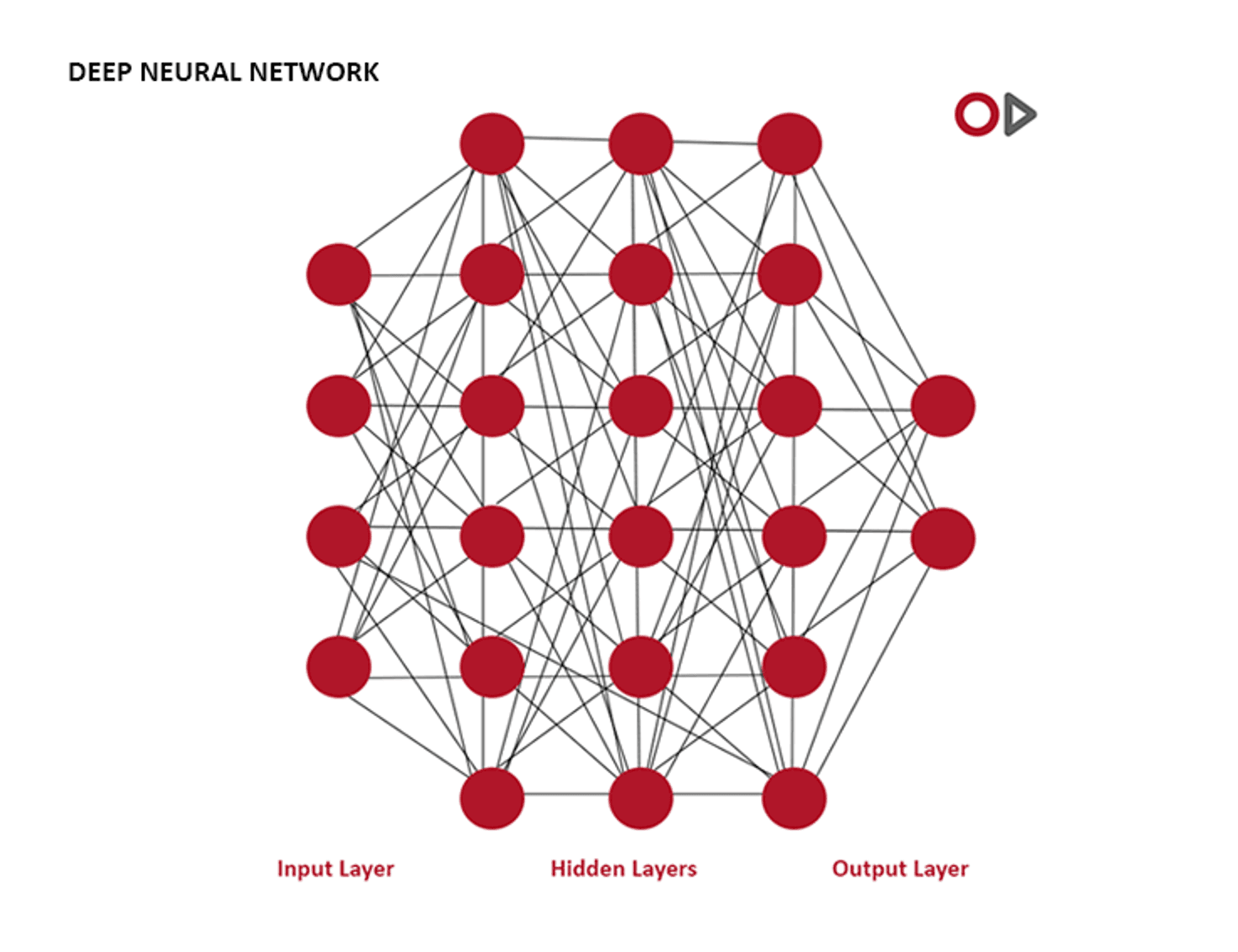
Each neuron combines multiple input signals to create an output signal. These are combined with multiple layers, which each solve a specific task. The first layer – can be compared to the senses of humans and can recognise basic meaning.
In subsequent hidden layers, findings are combined over and over again until a result is available in the output layer. Each layer is optimised with large amounts of data through "trial and error" to detect similarities and create meaning.
‘Neural networks are algorithms that can interpret sensory data via machine perception and label or group the raw data. They are designed to recognise numerical patterns contained in vectors that need to transform all real-world data (images, sounds, text, time series, etc.)’ (geeksforgeeks, 2023).
Figure 1, below, demonstrates the Deep Neural Networks (DNNs) which include the input layer, the hidden layers and the output layer. It is worth noting here that there are many(!) hidden layers – not only the three pictured here as an example.
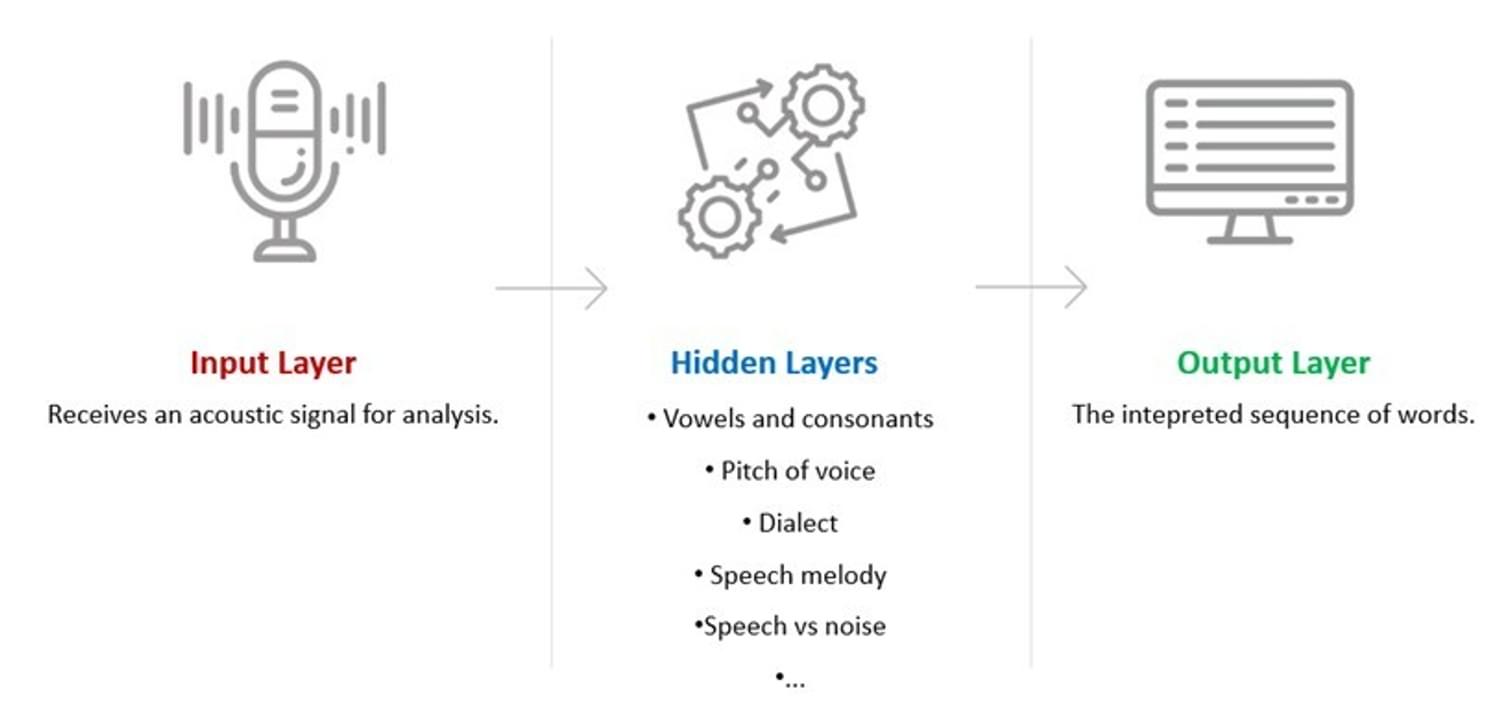
In speech technology, the input for the input layer consists of the sounds to be interpreted.
The example below demonstrates a medical audio file. This is an example of the input for the 'input layer':

The hidden layers each take the role of depicting vowels and consonants to define words by determining, for example factors including pitch of voice, dialect, speech melody and speech vs. noise. These hidden layers will then come together to determine the interpreted sequence of words with the highest overall probabilities.
The output layer then presents with the defined dictated words. For example, “Patient presented today with right shoulder pain and stiffness.”
Below here is an illustration of the layers within the network.
Deep learning
Deep learning is a type of machine learning inspired by the structure of the human brain. In terms of deep learning, this structure is called an artificial neural network. Deep learning indicates the vast layers within a network.
Neural networks are at the core of speech technology, allowing us to build highly accurate and adaptable systems for speech recognition, synthesis, and understanding.
Why do we need DNNs in speech recognition?
Traditionally, speech technology and recognition has been based on machine learning algorithms which use pre-engineered features to develop predictions. For example, based on the input of sounds transmitted, pre-determined rules, learning and probability create an output sequence of interpreted words and sentences. This is then trained and developed over time to build accuracy. This has functioned very well and resulted in significant productivity and efficiency savings for users across the globe. This technology is still widely used today to support healthcare professionals, lawyers, customer service professionals, in education, and entertainment. But these technologies have required time to train individual voice profiles and have always had limitations. With the introduction of DNNs in speech recognition there is no training necessary. The vast amount of data used in training models means that the results are incomparable with previous technology. The results are far superior.
The key differentiator with DNNs is that the output is the total sum of everything – it is not an output based on limited statistics alone. DNNs have the ability to go far beyond, fill gaps and use AI to provide a far more comprehensive and complete picture. For example, in instances where there may be fewer common pronunciations or variations, the network will work through thousands of possibilities to arrive at the most logical output (considering every input detail available).
With the introduction of DNNs, speech technology has been completely revolutionised. The result of which being clinicians, lawyers, and business professionals across the globe, regardless of the accents, environments and dictation devices, can now receive the highest levels of accuracy from the first dictation.
Interested in learning more about our DNN based speech recognition SDK? Request more information
References:
Azevedo FA;Carvalho LR;Grinberg LT;Farfel JM;Ferretti RE;Leite RE;Jacob Filho W;Lent R;Herculano-Houzel S; (10 April, 2009) Equal numbers of neuronal and nonneuronal cells make the human brain an isometrically scaled-up primate brain, The Journal of comparative neurology. Available at: https://pubmed.ncbi.nlm.nih.go... (Accessed: 17 October 2023).
Chatterjee, Chayan; Wen, Linqing; Vinsen, Kevin; Kovalam, Manoj; Datta, Amitava; (13 September, 2019) Using Deep Learning to Localize Gravitational Wave Sources - Scientific Figure on ResearchGate. Available from: https://www.researchgate.net/f... (Accessed: 8 September, 2023)
Yasar, Kinza; Deep neural network on Tech Target. Available from: https://www.techtarget.com/searchenterpriseai/definition/neural-network (accessed 6 Nov, 2023)
Difference between a Neural Network and a Deep Learning System on GeeksforGeeks. Available from Difference between a Neural Network and a Deep Learning System - GeeksforGeeks (Accessed 16 October, 2023)
Sign up to our newsletter and stay up to date with all the news, views and promotional offers.
Recognosco GmbH
Donau-City-Straße 1
1220 Vienna
Austria
Phone: +43 1 9346180-0
Email: contact@recognosco.net
